|
Currently, I am a reinforcement learning researcher at Netease Games-Fuxi AI Lab. My work mainly focuses on the application of reinforcement learning in the game life cycle, and also includes using reinforcement learning to train LLM and use LLM for control. Before that, I obtained a Ph.D. from Tianjin University under the guidance of Professor Jianye Hao. I believe (MA)RL will further change the world.
|

|
|
I have an interest in using deep reinforcement learning in multi-agent systems. I believe that MAS (Multi-Agent) is a more realistic description of the (large) problem in the real world. I also believe that deep reinforcement learning can solve more complex practical problems in the MAS field. |
|
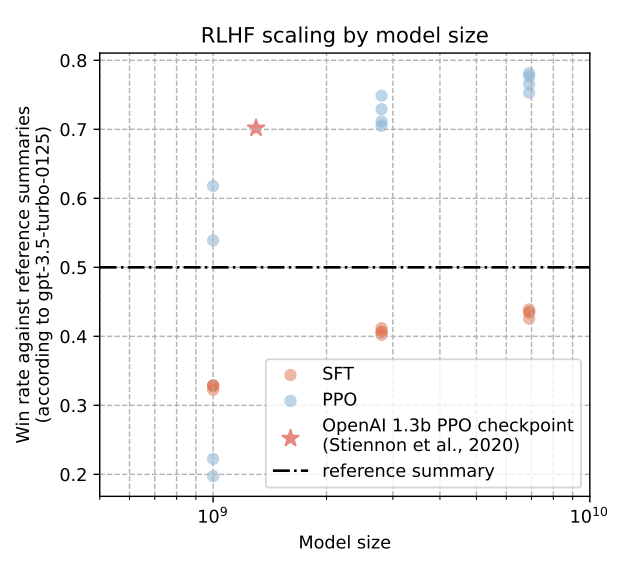
Shengyi Huang, Michael Noukhovitch, Arian Hosseini, Kashif Rasul, Weixun Wang, Lewis Tunstall COLM 2024 This work is the first to openly reproduce the Reinforcement Learning from Human Feedback (RLHF) scaling behaviors reported in OpenAI's seminal TL;DR summarization work. We create an RLHF pipeline from scratch, enumerate over 20 key implementation details, and share key insights during the reproduction. Our RLHF-trained Pythia models demonstrate significant gains in response quality that scale with model size, with our 2.8B, 6.9B models outperforming OpenAI's released 1.3B checkpoint. We publicly release the trained model checkpoints and code to facilitate further research and accelerate progress in the field. |
|
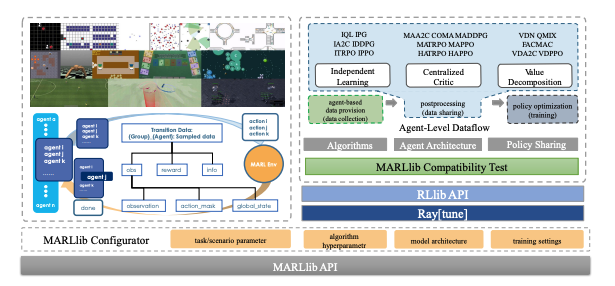
Siyi Hu, Yifan Zhong, Minquan Gao, Weixun Wang, Hao Dong, Xiaodan Liang, Zhihui Li, Xiaojun Chang, Yaodong Yang JMLR - 24(315):1−23, 2023. A significant challenge facing researchers in the area of multi-agent reinforcement learning (MARL) pertains to the identification of a library that can offer fast and compatible development for multi-agent tasks and algorithm combinations, while obviating the need to consider compatibility issues. In this paper, we present MARLlib, a library designed to address the aforementioned challenge by leveraging three key mechanisms: 1) a standardized multi-agent environment wrapper, 2) an agent-level algorithm implementation, and 3) a flexible policy mapping strategy. By utilizing these mechanisms, MARLlib can effectively disentangle the intertwined nature of the multi-agent task and the learning process of the algorithm, with the ability to automatically alter the training strategy based on the current task's attributes. The MARLlib library's source code is publicly accessible on GitHub: url |
|
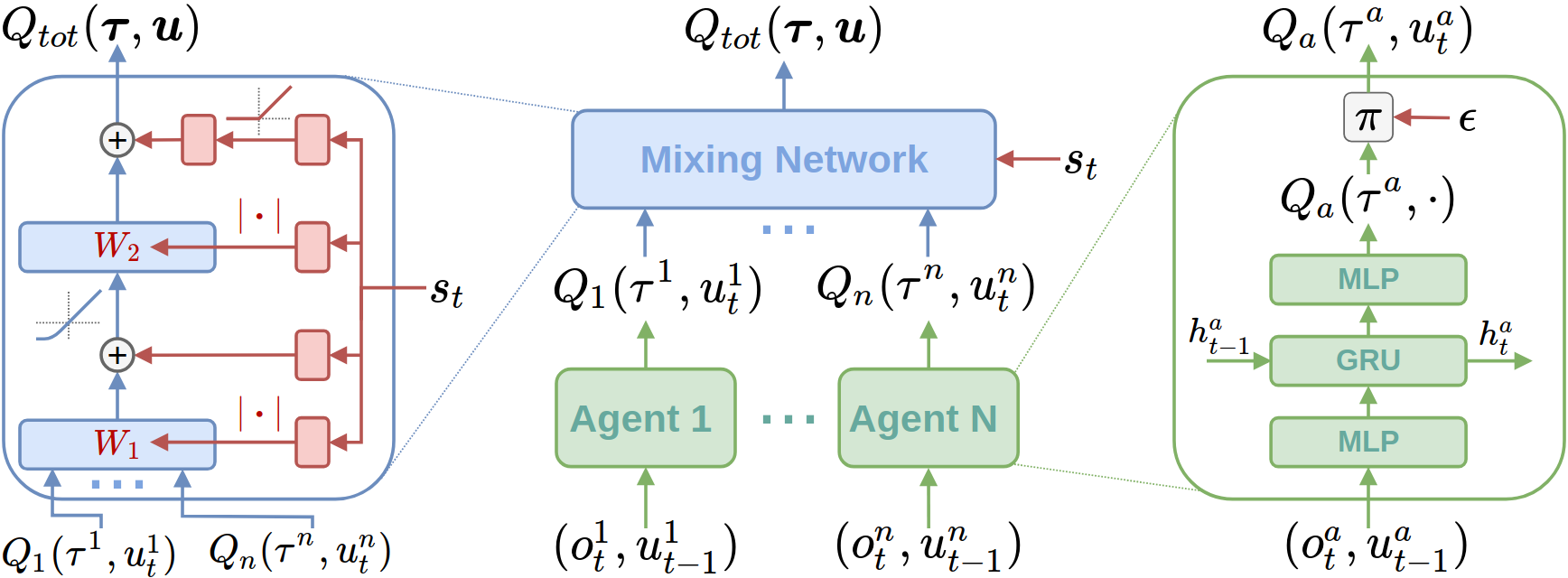
Jian Hu, Siying Wang, Siyang Jiang, Weixun Wang ICLR 2023 blog QMIX, a very classical multi-agent reinforcement learning (MARL) algorithm, is often considered to be a weak performance baseline due to its representation capability limitations. However, we found that by improving the implementation techniques of QMIX we can enable it to achieve state-of-the-art on the StarCraft Multi-Agent Challenge (SMAC) testbed. Furthermore, the key factor of the monotonicity constraint of QMIX was found in this post, we tried to explain its role and corroborated its superior performance by combining it with another actor-critic style algorithm. We have open-sourced the code at https://github.com/hijkzzz/pymarl2 for researchers to evaluate the effects of these proposed techniques. |
|
|
Tianze Zhou, Fubiao Zhang, Kun Shao, Zipeng Dai, Kai Li, Wenhan Huang, Weixun Wang, Bin Wang, Dong Li, Wulong Liu, Jianye Hao Transactions on Games 2023 We propose a level-adaptive MARL framework called “LA-QTransformer”, to realize the knowledge transfer on the coordination level via efficiently decomposing the agent coordination into multi-level coalition patterns for different agents. Compatible with centralized training with decentralized execution (CTDE) regime, LA-QTransformer utilizes the LevelAdaptive Transformer to generate suitable coalition patterns and then realizes the credit assignment for each agent. Besides, to deal with unexpected changes in the number of agents in the coordination transfer phase, we design a policy network called “Population invariant agent with Transformer (PIT)” to adapt dynamic observation and action space. We evaluate the LAQTransformer and PIT in the StarCraft II micro-management benchmark by comparing them with several state-of-the-art MARL baselines. The experimental results demonstrate the superiority of LA-QTransformer and PIT and verify the feasibility of coordination knowledge transfer. |
|
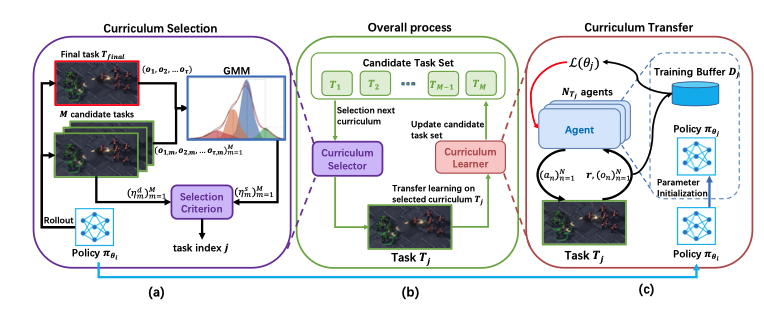
Jizhou Wu, Tianpei Yang, Xiaotian Hao, Jianye Hao, Yan Zheng, Weixun Wang, Matthew E. Taylor AAMAS 2023 We propose a novel ACL framework, PrOgRessive mulTiagent Automatic curricuLum (PORTAL), for MASs. PORTAL selects curricula according to two criteria: 1) How difficult is a task, relative to the learners' current abilities? 2) How similar is a task, relative to the final task? By learning a shared feature space between tasks, PORTAL is able to characterize different tasks based on the distribution of features and select those that are similar to the final task. Also, the shared feature space can effectively facilitate the policy transfer between curricula. Experimental results show that PORTAL can train agents to master extremely hard cooperative tasks, which cannot be achieved with previous state-of-the-art MARL algorithms. |
|
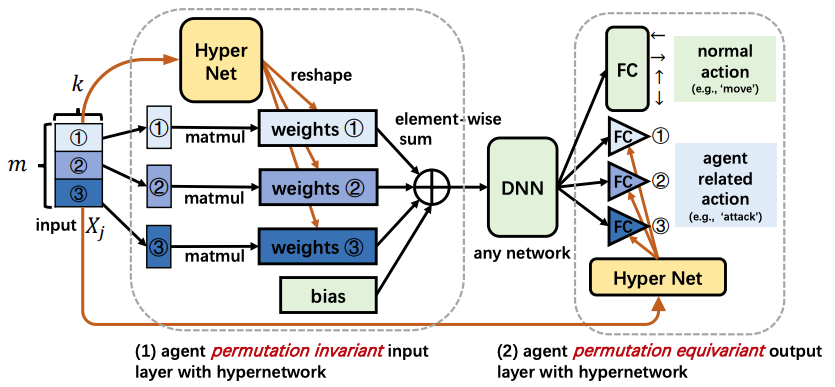
Jianye Hao, Xiaotian Hao, Hangyu Mao, Weixun Wang, Yaodong Yang, Dong Li, Yan Zheng, Zhen Wang, ICLR 2023 We propose two novel designs to achieve PI, while avoiding the above limitations. The first design permutes the same but differently ordered inputs back to the same order and the downstream networks only need to learn function mapping over fixed-ordering inputs instead of all permutations, which is much easier to train. The second design applies a hypernetwork to generate customized embedding for each component, which has higher representational capacity than the previous embedding-sharing method. Empirical results on the SMAC benchmark show that the proposed method achieves 100% win-rates in almost all hard and super-hard scenarios (never achieved before), and superior sample-efficiency than the state-of-the-art baselines by up to 400%. |
|
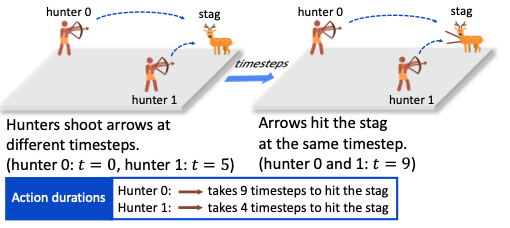
Wei Qiu, Weixun Wang, Rundong Wang, Bo An, Yujing Hu, Svetlana Obraztsova, Zinovi Rabinovich, Jianye Hao, Yingfeng Chen, Changjie Fan AAMAS 2023 We develop an algorithmic framework for MARL with off-beat actions. We then propose a novel episodic memory, LeGEM, for model-free MARL algorithms. LeGEM builds agents' episodic memories by utilizing agents' individual experiences. It boosts multi-agent learning by addressing the challenging temporal credit assignment problem raised by the off-beat actions via our novel reward redistribution scheme, alleviating the issue of non-Markovian reward. We evaluate LeGEM on various multi-agent scenarios with off-beat actions, including Stag-Hunter Game, Quarry Game, Afforestation Game, and StarCraft II micromanagement tasks. Empirical results show that LeGEM significantly boosts multi-agent coordination and achieves leading performance and improved sample efficiency. |
|
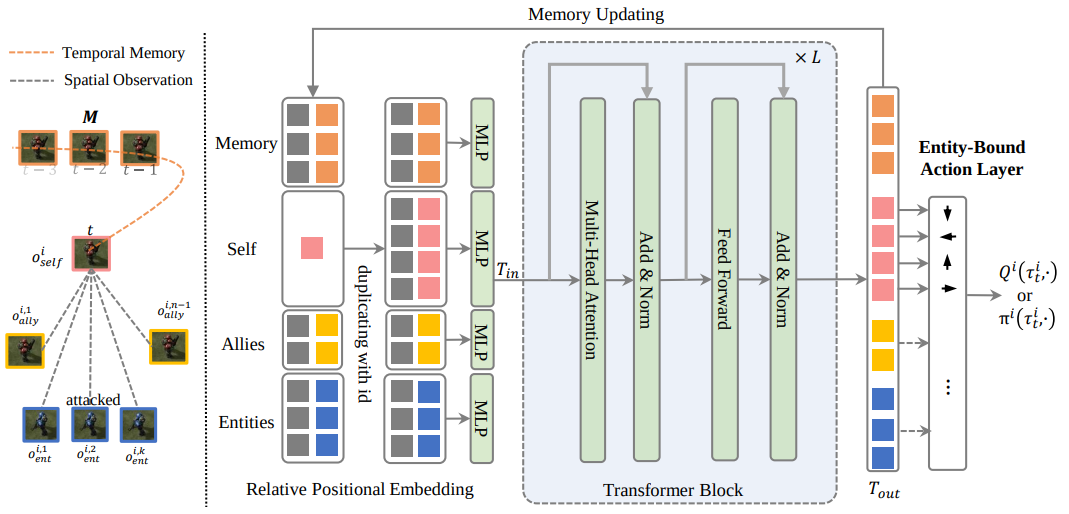
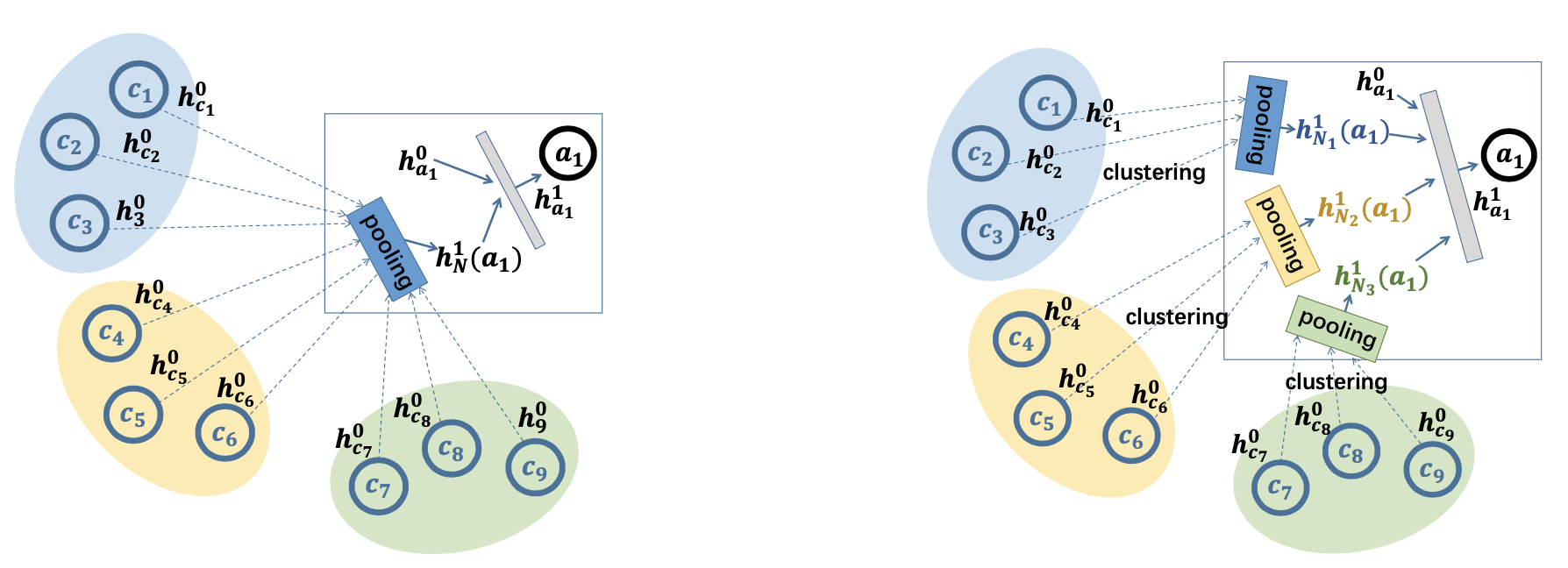
Yaodong Yang, Guangyong Chen, Weixun Wang, Xiaotian Hao, Jianye HAO, Pheng-Ann Heng NeurIPS 2022 we propose the Agent Transformer Memory (ATM) network with a transformer-based memory. First, ATM utilizes the transformer to enable the unified processing of the factored environmental entities and memory. Inspired by the human’s working memory process where a limited capacity of information temporarily held in mind can effectively guide the decision-making, ATM updates its fixed-capacity memory with the working memory updating schema. Second, as agents' each action has its particular interaction entities in the environment, ATM parses the action space to introduce this action’s semantic inductive bias by binding each action with its specified involving entity to predict the state-action value or logit. |

|
Shengyi Huang, Anssi Kanervisto, Antonin Raffin, Weixun Wang, Santiago Ontañón, Rousslan Fernand Julien Dossa Arxiv we show A2C is a special case of PPO. We present theoretical justifications and pseudocode analysis to demonstrate why. To validate our claim, we conduct an empirical experiment using Stable-baselines3, showing A2C and PPO produce the exact same models when other settings are controlled. |
|
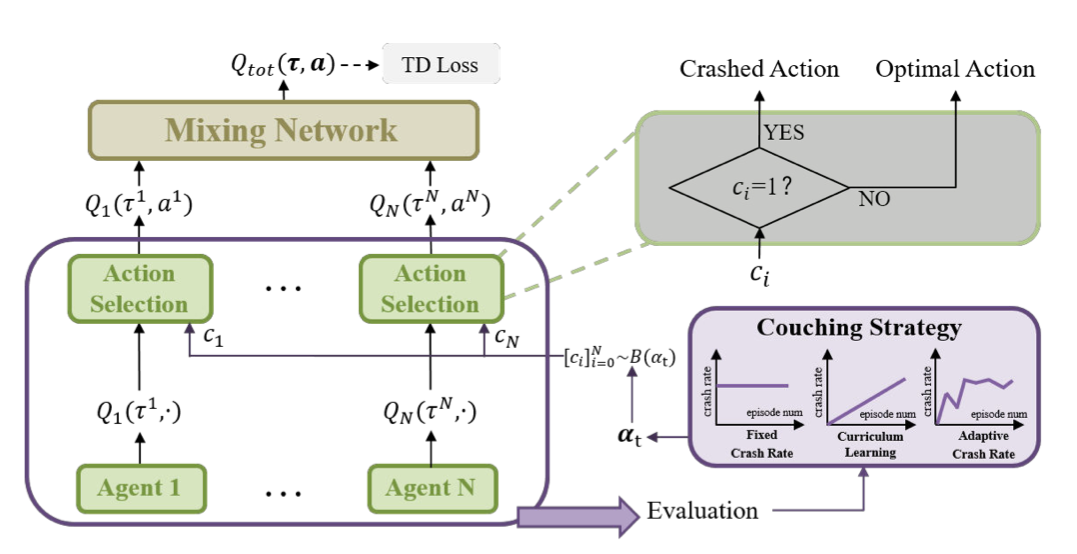
Jian Zhao, Youpeng Zhao, Weixun Wang, Mingyu Yang, Xunhan Hu, Wengang Zhou, Jianye Hao, Houqiang Li Arxiv we present a formal formulation of a cooperative multi-agent reinforcement learning system with unexpected crashes. To enhance the robustness of the system to crashes, we propose a coach-assisted multi-agent reinforcement learning framework, which introduces a virtual coach agent to adjust the crash rate during training. We design three coaching strategies and the re-sampling strategy for our coach agent. |
|
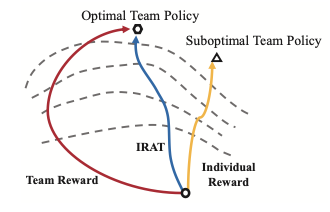
Li Wang, Yupeng Zhang, Yujing Hu, Weixun Wang, Chongjie Zhang, Yang Gao, Jianye Hao, Tangjie Lv, Changjie Fan ICML 2022 We propose Individual Reward Assisted Team Policy Learning(IRAT), which learns two policies for each agent from the dense individual reward and the sparse team reward with discrepancy constraints for updating the two policies mutually. Experimental results in different scenarios, such as the Multi-Agent Particle Environment and the Google Research Football Environment, show that IRAT significantly outperforms the baseline methods and can greatly promote team policy learning without deviating from the original team objective, even when the individual rewards are misleading or conflict with the team rewards. |

|
Shengyi Huang, Rousslan Fernand Julien Dossa, Antonin Raffin, Anssi Kanervisto, Weixun Wang ICLR 2022 Blog This blog post takes a step back and focuses on delivering a thorough reproduction of PPO in all accounts, as well as aggregating, documenting, and cataloging its most salient implementation details. This blog post also points out software engineering challenges in PPO and further efficiency improvement via the accelerated vectorized environments. With these, we believe this blog post will help people understand PPO faster and better, facilitating customization and research upon this versatile RL algorithm. |
|
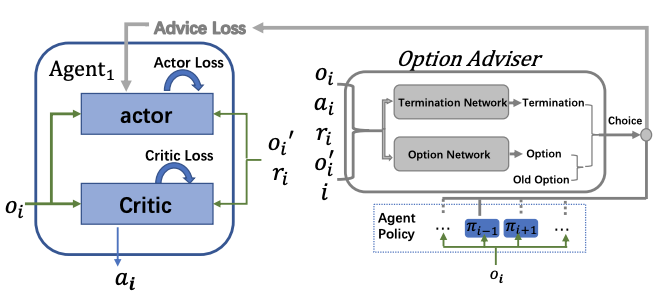
Tianpei Yang*(Equal contribution), Weixun Wang*(Equal contribution), Hongyao Tang*(Equal contribution), Jianye Hao, Zhaopeng Meng,Hangyu Mao, Dong Li, Wulong Liu, Chengwei Zhang, Yujing Hu, Yingfeng Chen, Changjie Fan NeurIPS 2021 We propose a novel Multiagent Policy Transfer Framework (MAPTF) to improve MARL efficiency. MAPTF learns which agent's policy is the best to reuse for each agent and when to terminate it by modeling multiagent policy transfer as the option learning problem. And we propose a novel option learning algorithm, the successor representation option learning to solve it by decoupling the environment dynamics from rewards and learning the option-value under each agent's preference. |
|
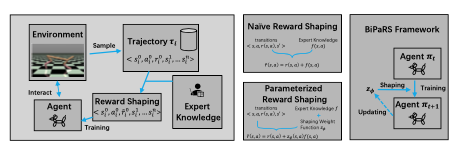
Yujing Hu, Weixun Wang, Hangtian Jia, Yixiang Wang, Yingfeng Chen, Jianye Hao, Feng Wu, Changjie Fan NeurIPS 2020 We formulate the utilization of shaping rewards as a bi-level optimization problem, where the lower level is to optimize policy using the shaping rewards and the upper level is to optimize a parameterized shaping weight function for true reward maximization. We formally derive the gradient of the expected true reward with respect to the shaping weight function parameters and accordingly propose three learning algorithms based on different assumptions. Experiments in sparse-reward cartpole and MuJoCo environments show that our algorithms can fully exploit beneficial shaping rewards, and meanwhile ignore unbeneficial shaping rewards or even transform them into beneficial ones. |
|
Xiaotian Hao, Junqi Jin, Jin Li, Weixun Wang, Yi Ma, Jianye Hao, Zhenzhe Zheng, Han Li, Jian Xu, Kun Gai IJCAI 2020 We propose NeuSearcher which leverage the knowledge learned from previously instances to solve new problem instances. Specifically, we design a multichannel graph neural network to predict the threshold of the matched edges, by which the search region could be significantly reduced. We further propose a parallel heuristic search algorithm to iteratively improve the solution quality until convergence. Experiments on both open and industrial datasets demonstrate that NeuSearcher can speed up 2 to 3 times while achieving exactly the same matching solution compared with the state-of-the-art approximation approaches. |
|
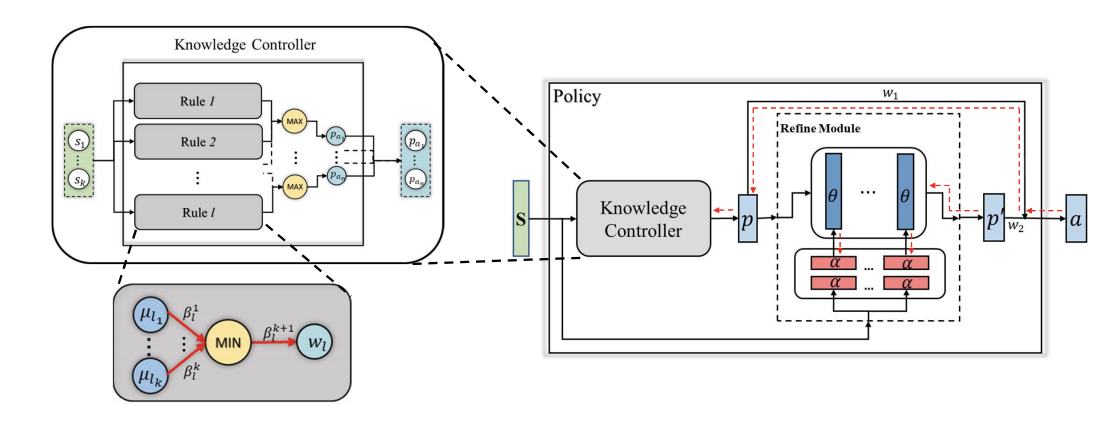
Peng Zhang, Jianye Hao, Weixun Wang, Hongyao Tang, Yi Ma, Yihai Duan, Yan Zheng IJCAI 2020 We propose knowledge guided policy network (KoGuN), a novel framework that combines human prior suboptimal knowledge with reinforcement learning. Our framework consists of a fuzzy rule controller to represent human knowledge and a refine module to fine-tune suboptimal prior knowledge. The proposed framework is end-to-end and can be combined with existing policy-based reinforcement learning algorithm. |
|
Weixun Wang, Tianpei Yang Yong Liu, Jianye Hao, Xiaotian Hao, Yujing Hu, Yingfeng Chen, Changjie Fan, Yang Gao ICLR 2020 In this paper, we propose a novel network architecture, named Action Semantics Network (ASN), that explicitly represents such action semantics between agents. ASN characterizes different actions' influence on other agents using neural networks based on the action semantics between agents. |
|
Tianpei Yang, Jianye Hao, Zhaopeng Meng, Zongzhang Zhang, Weixun Wang, Yujing Hu, Yingfeng Chen, Changjie Fan, Zhaodong Wang, Jiajie Peng AAMAS 2020 (abstract) + IJCAI 2020 We propose a novel Policy Transfer Framework (PTF) to accelerate RL by taking advantage of this idea. Our framework learns when and which source policy is the best to reuse for the target policy and when to terminate it by modeling multi-policy transfer as the option learning problem. |
|
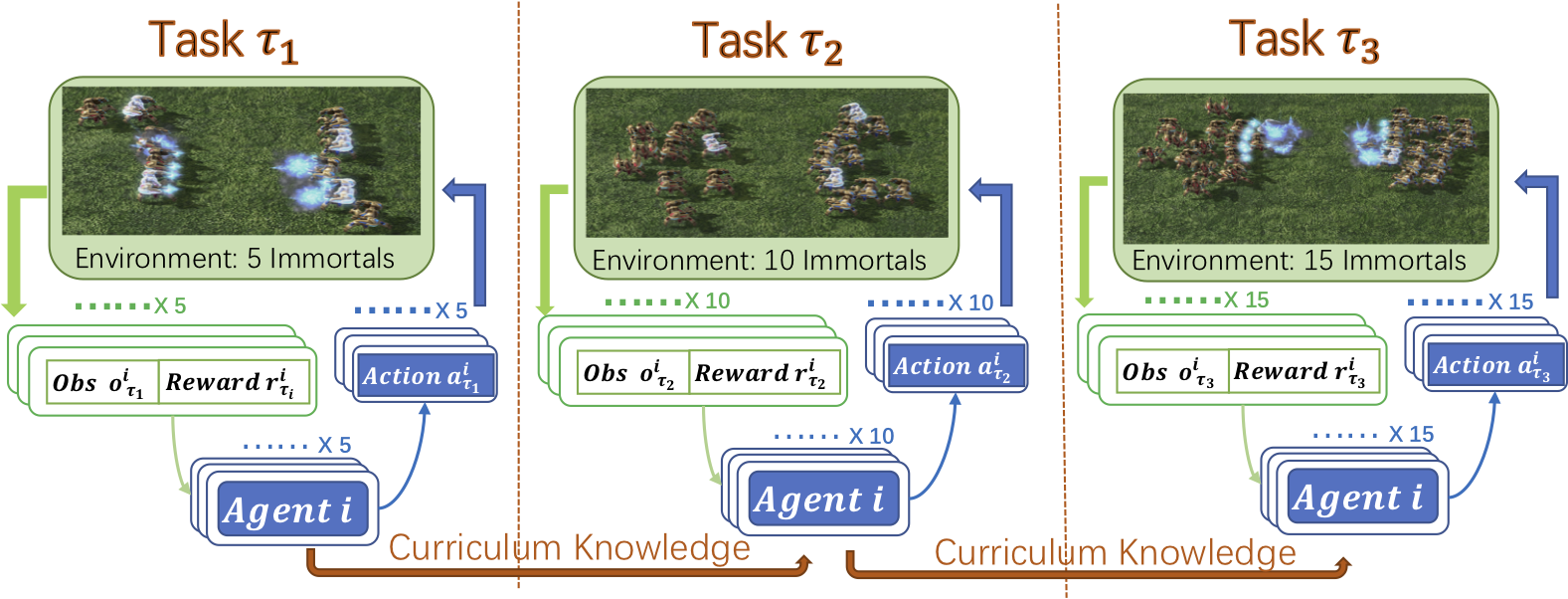
Weixun Wang, Tianpei Yang, Yong Liu, Jianye Hao, Xiaotian Hao, Yujing Hu, Yingfeng Chen, Changjie Fan, Yang Gao AAAI 2020 In this paper, we design a novel Dynamic Multiagent Curriculum Learning (DyMA-CL) to solve large-scale problems by starting from learning on a multiagent scenario with a small size and progressively increasing the number of agents. We propose three transfer mechanisms across curricula to accelerate the learning process. Moreover, due to the fact that the state dimension varies across curricula,, and existing network structures cannot be applied in such a transfer setting since their network input sizes are fixed. Therefore, we design a novel network structure called Dynamic Agent-number Network (DyAN) to handle the dynamic size of the network input. |
|
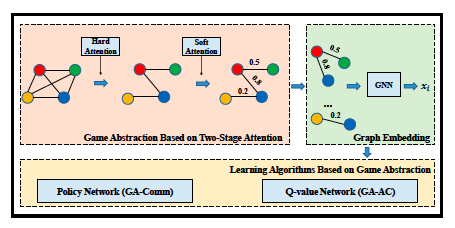
Yong Liu*(Equal contribution), Weixun Wang*(Equal contribution), Yujing Hu, Jianye Hao, Xingguo Chen, Yang Gao AAAI 2020 In this paper, we model the relationship between agents by a complete graph and purpose a novel game abstraction mechanism based on two-stage attention network (G2ANet), which can indicate whether there is an interaction between two agents and the importance of the interaction. We integrate this detection mechanism into graph neural network-based multi-agent reinforcement learning for conducting game abstraction and propose two novel learning algorithms GA-Comm and GA-AC. We conduct experiments in Traffic Junction and Predator-Prey. The results indicate that the proposed methods can simplify the learning process and meanwhile get better asymptotic performance compared with state-of-the-art algorithms. |
|
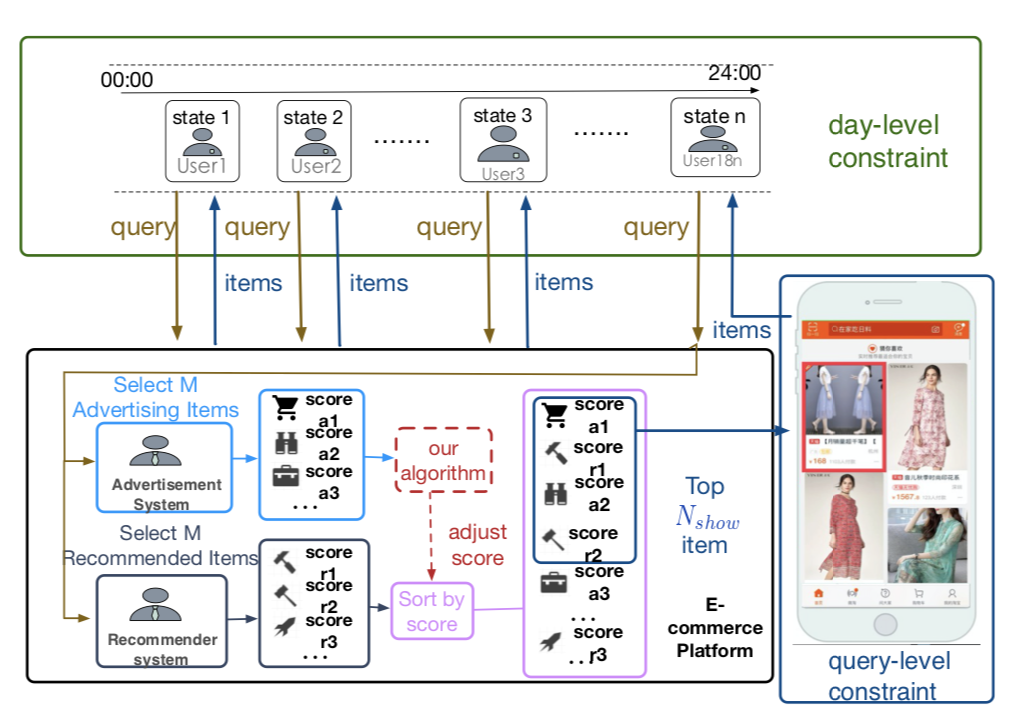
Weixun Wang, Junqi Jin, Jianye Hao, Chunjie Chen, Chuan Yu, Weinan Zhang, Jun Wang, Xiaotian Hao, Yixi Wang, Han Li, Jian Xu, Kun Gai CIKM 2019 In this paper, we investigate the problem of advertising with adaptive exposure, in which the number of ad slots and their locations can dynamically change over time based on their relative scores with recommendation products. |
|
Xiaotian Hao *(Equal contribution), Weixun Wang *(Equal contribution), Jianye Hao, Yaodong Yang AAMAS 2019 The first to combine self imitation learning with GAIL and propose a novel framework IGASIL to address the multiagent coordination problems. |

|
Weixun Wang, Jianye Hao, Yixi Wang, Matthew Taylor AAMAS 2018 Workshop ALA, DAI 2019 (Best Paper Award) In this work, we propose a deep multiagent reinforcement learning approach that investigates the evolution of mutual cooperation in SPD games. |